# ================================================================
# Case Study 6 — Historical shape (ggplot2) + OC curves (base R)
# - One-sided sampling (Ac = 0), uniform axes across OC figures
# - Legend with AQL / LTPD / LQ20 values included
# - Four separate OC plots: n = 32, 50, 80, 125
# ================================================================
suppressPackageStartupMessages(library(ggplot2))
set.seed(123)
# -----------------------------
# 0) Setup (one-sided LSL case)
# -----------------------------
LSL <- 98.0
U <- 102.0 # only for the illustrative historical distribution
# A left-skewed Beta(alpha, beta) on [LSL, U] when alpha > beta:
alpha_hat <- 8
beta_hat <- 2.6
# Generator for the illustrative “historical” data:
# by construction, ALL values are >= LSL (no OOS).
r_hist <- function(n) LSL + (U - LSL) * rbeta(n, alpha_hat, beta_hat)
# -----------------------------
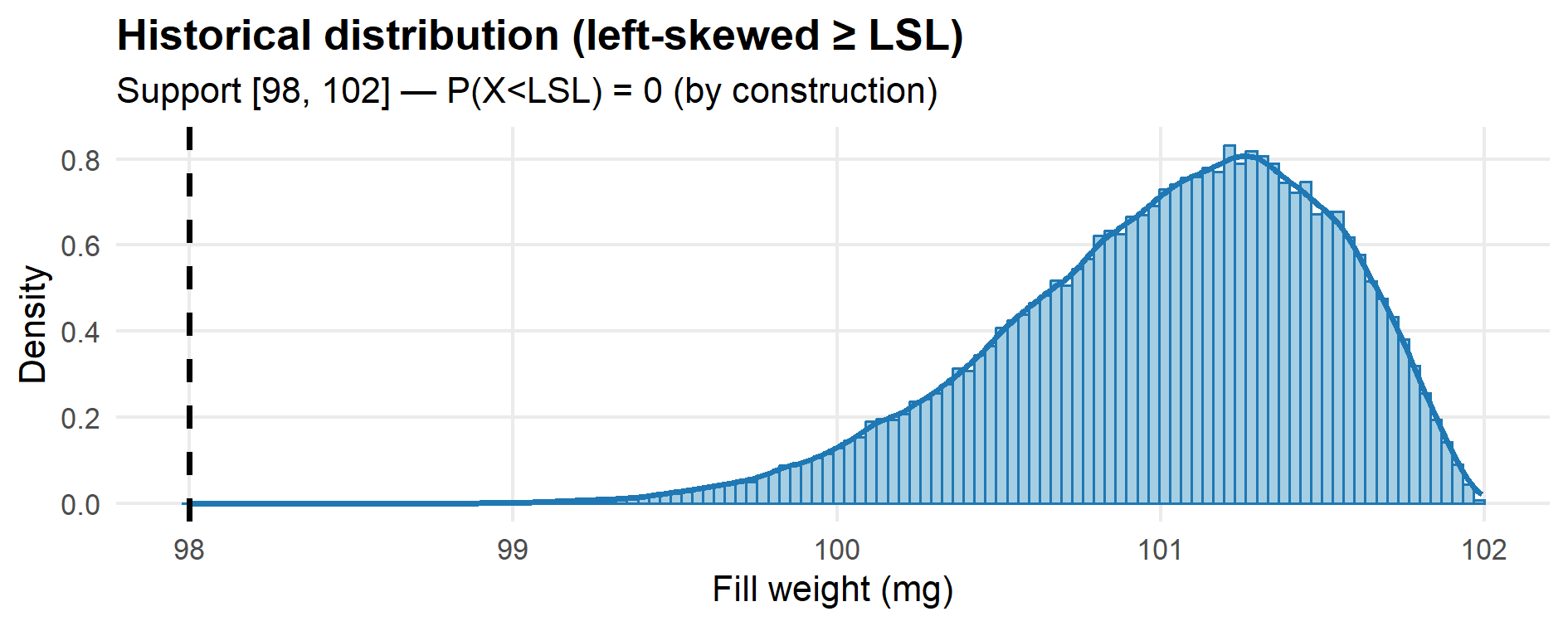
# 1) Historical distribution
# -----------------------------
hist_x <- r_hist(100000)
stopifnot(all(hist_x >= LSL)) # defensive check
p_hist <- ggplot(data.frame(x = hist_x), aes(x)) +
geom_histogram(aes(y = after_stat(density)),
bins = 120, fill = "#a6cee3", color = "#1f78b4") +
geom_density(linewidth = 1.1, color = "#1f78b4") +
geom_vline(xintercept = LSL, linetype = 2, linewidth = 1) +
labs(title = "Historical distribution (left-skewed ≥ LSL)",
subtitle = sprintf("Support [%g, %g] — P(X<LSL) = 0 (by construction)", LSL, U),
x = "Fill weight (mg)", y = "Density") +
theme_minimal(base_size = 13) +
theme(plot.title = element_text(face = "bold"),
panel.grid.minor = element_blank())
print(p_hist)
# ggsave("fig12_1_historical.png", p_hist, width = 10, height = 3.6, dpi = 150)
# -------------------------------------
# 2) OC settings and helper functions
# -------------------------------------
# Uniform axes across all OC plots (for visual comparability)
xlim_percent <- c(0, 16) # x: 0–16% defectives
ylim_common <- c(0, 0.40) # y: Pa 0.00–0.40
# Grid of true defect rates p (in fraction). We will plot in percent.
p_grid <- seq(0, xlim_percent[2] / 100, by = 0.002)
# Monte Carlo reps for empirical Pa; increase if you want smoother dots
reps <- 20000
# Empirical acceptance probability at a given p
Pa_empirical <- function(n, Ac, p, reps = 20000) {
# For Ac = 0, accept if K = 0 with K ~ Bin(n, p).
mean(rbinom(reps, size = n, prob = p) <= Ac)
}
# One OC figure (base R): empirical (points) + binomial theory (dashed line)
plot_OC_base <- function(n, Ac = 0L) {
# Curves
Pa_emp <- sapply(p_grid, function(p) Pa_empirical(n, Ac, p, reps))
Pa_the <- pbinom(Ac, n, p_grid) # For Ac=0, equals (1 - p)^n
# Risk points (closed form for Ac = 0)
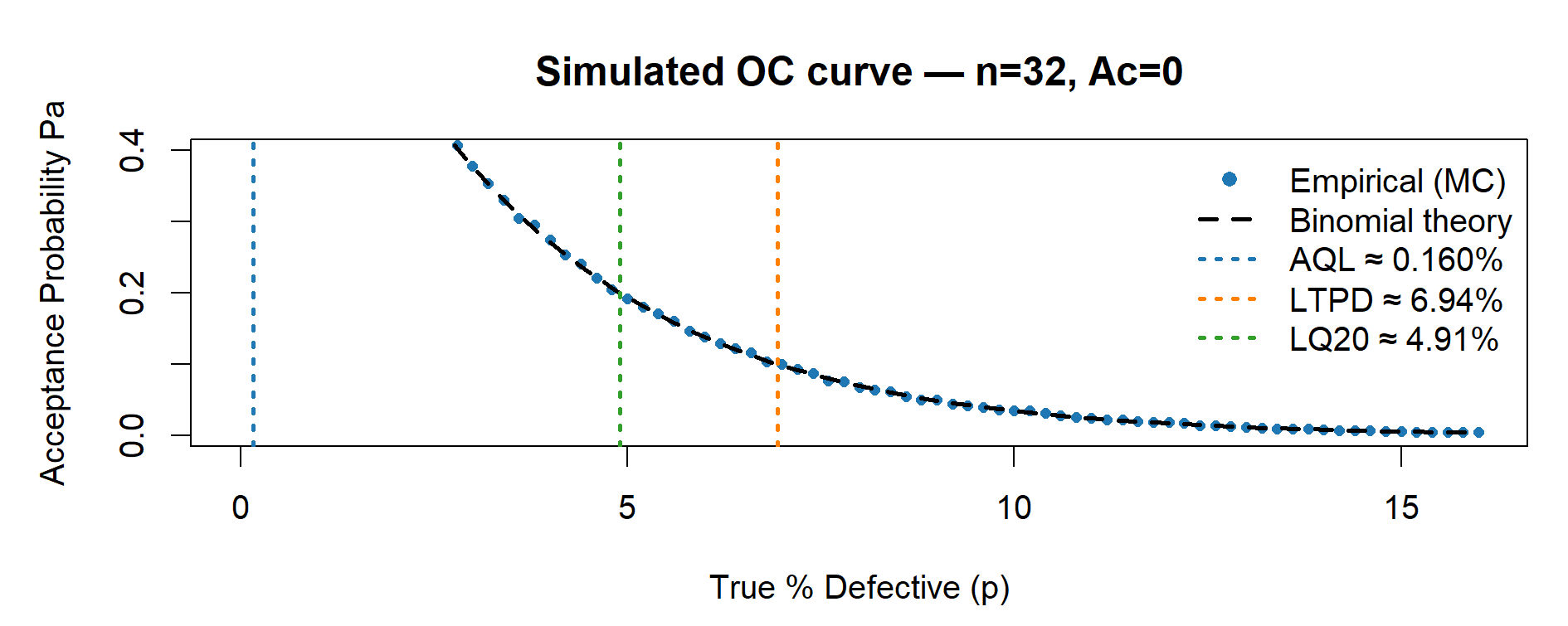
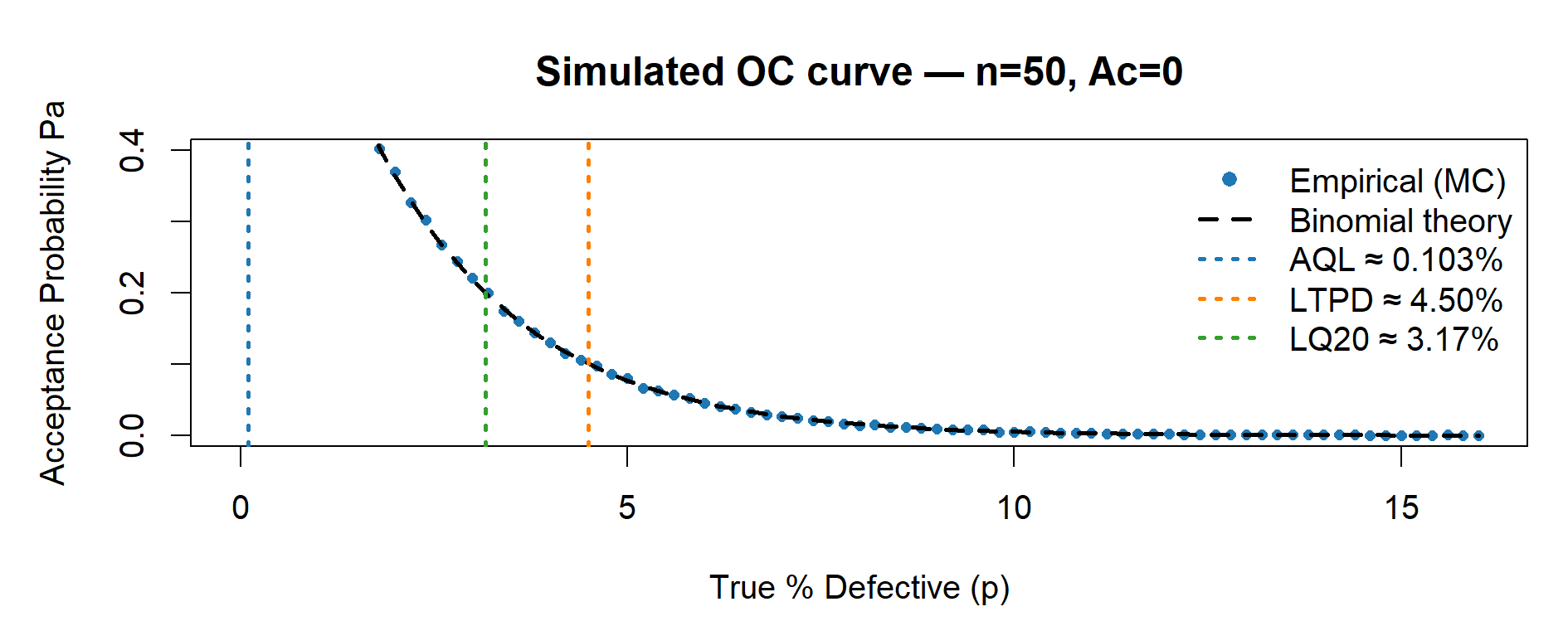
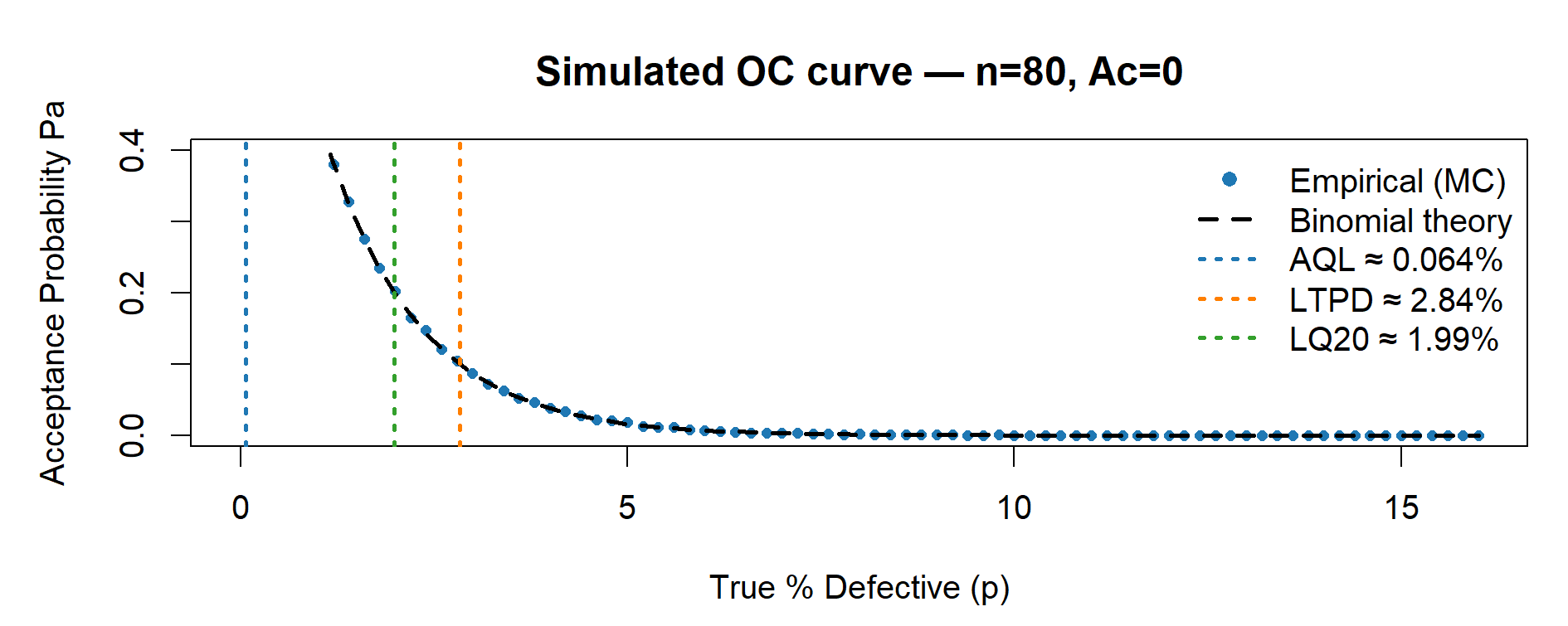
p_AQL <- 1 - 0.95^(1 / n) # Pa ~ 0.95
p_LTPD <- 1 - 0.10^(1 / n) # Pa ~ 0.10
p_LQ20 <- 1 - 0.20^(1 / n) # Pa ~ 0.20
# Plot
par(mar = c(4.5, 4.8, 3.5, 1))
plot(p_grid * 100, Pa_emp,
type = "p", pch = 16, cex = 0.7, col = "#1f78b4",
xlim = xlim_percent, ylim = ylim_common,
xlab = "True % Defective (p)", ylab = "Acceptance Probability Pa",
main = sprintf("Simulated OC curve — n=%d, Ac=%d", n, Ac))
lines(p_grid * 100, Pa_the, lty = 2, lwd = 2, col = "#000000") # Binomial theory
# Vertical markers (thicker, color-coded)
abline(v = 100 * p_AQL, lty = 3, lwd = 2, col = "#1f78b4") # AQL (blue)
abline(v = 100 * p_LTPD, lty = 3, lwd = 2, col = "#ff7f00") # LTPD (orange)
abline(v = 100 * p_LQ20, lty = 3, lwd = 2, col = "#33a02c") # LQ20 (green)
# Single legend with numeric values
legend("topright",
legend = c("Empirical (MC)",
"Binomial theory",
sprintf("AQL \u2248 %.3f%%", 100 * p_AQL),
sprintf("LTPD \u2248 %.2f%%", 100 * p_LTPD),
sprintf("LQ20 \u2248 %.2f%%", 100 * p_LQ20)),
col = c("#1f78b4", "#000000", "#1f78b4", "#ff7f00", "#33a02c"),
pch = c(16, NA, NA, NA, NA),
lty = c(NA, 2, 3, 3, 3),
lwd = c(NA, 2, 2, 2, 2),
pt.cex = 1.0,
bty = "n")
# Return the three key percentages (for tables)
invisible(c(AQL = 100 * p_AQL, LTPD = 100 * p_LTPD, LQ20 = 100 * p_LQ20))
}
# --------------------------------------
# 3) Four separate OC plots (not a panel)
# --------------------------------------
risk_n32 <- plot_OC_base(32, Ac = 0L)
risk_n50 <- plot_OC_base(50, Ac = 0L)
risk_n80 <- plot_OC_base(80, Ac = 0L)
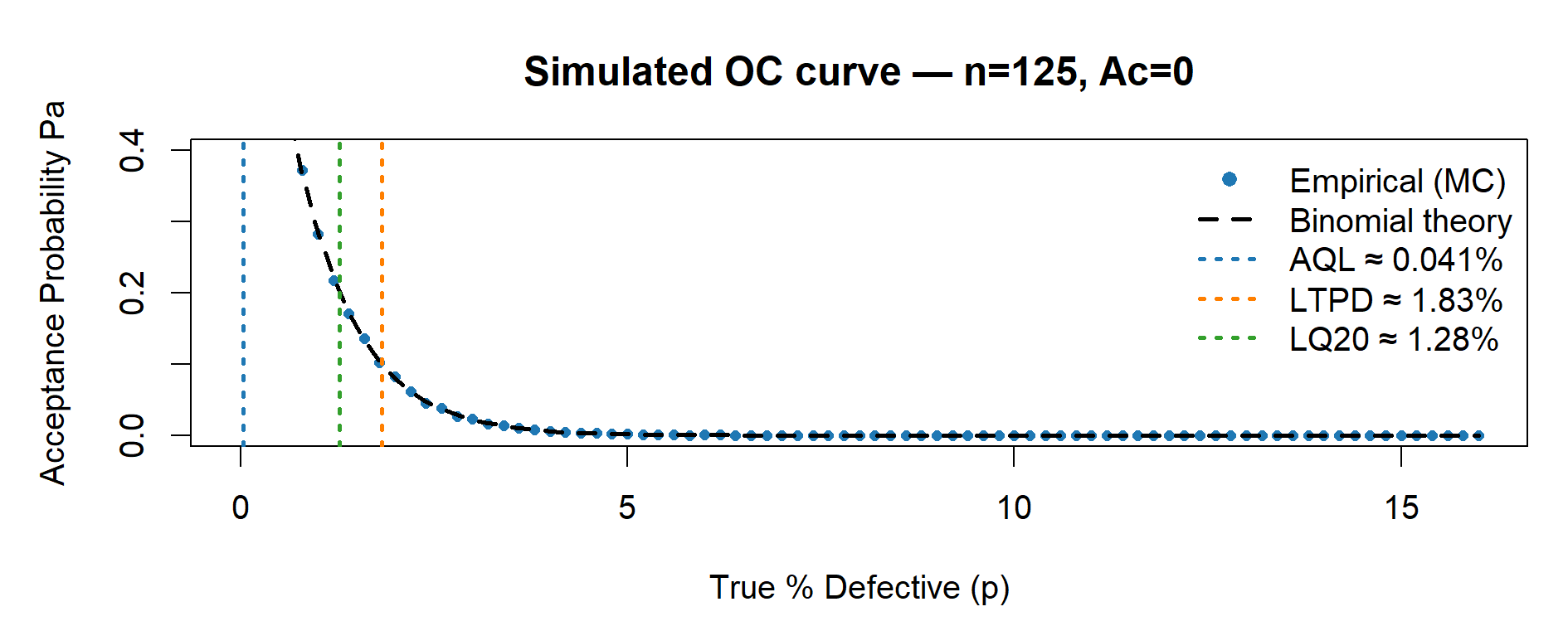
risk_n125 <- plot_OC_base(125, Ac = 0L)
# Optional PNG export:
# png("fig12_2_OC_n32.png", 1400, 500, res = 130); plot_OC_base(32); dev.off()
# png("fig12_3_OC_n50.png", 1400, 500, res = 130); plot_OC_base(50); dev.off()
# png("fig12_4_OC_n80.png", 1400, 500, res = 130); plot_OC_base(80); dev.off()
# png("fig12_5_OC_n125.png",1400, 500, res = 130); plot_OC_base(125); dev.off()
# --------------------------------------
# 4) Summary tables (percent + counts/1e6)
# --------------------------------------
# First, assemble a compact table with AQL, LTPD, LQ20 by plan:
risk_table <- rbind(
`n=32, Ac=0` = round(risk_n32, 3),
`n=50, Ac=0` = round(risk_n50, 3),
`n=80, Ac=0` = round(risk_n80, 3),
`n=125, Ac=0` = round(risk_n125, 3)
)
# Then build a data.frame with “clean” column names (no spaces)
risk_df <- data.frame(
Plan = rownames(risk_table),
AQL_pct = risk_table[, "AQL"],
LTPD_pct = risk_table[, "LTPD"],
LQ20_pct = risk_table[, "LQ20"]
)
# Counts per 1,000,000 units (helps with interpretability on slides)
risk_df$AQL_cnt_1e6 <- round(risk_df$AQL_pct / 100 * 1e6)
risk_df$LTPD_cnt_1e6 <- round(risk_df$LTPD_pct / 100 * 1e6)
risk_df$LQ20_cnt_1e6 <- round(risk_df$LQ20_pct / 100 * 1e6)
print(risk_df, row.names = FALSE)