
Figure 2.1 – Transformation process: from raw uniform random numbers to model-based random variates.
Monte Carlo simulations require randomness, but not all randomness is the same.
In this chapter, we clarify a crucial distinction:
Source: In practice, they are produced by a pseudo-random number generator (PRNG), which is deterministic but sufficiently random for most statistical simulations.
runif(5) # Generates 5 random numbers between 0 and 1
Key Point: These are “raw” random values — they are not yet tied to any specific probability distribution.
Key Point: Random variates represent real-world data models (e.g., assay values, tablet weights).
Example (conceptual): Transforming random numbers into normally distributed values.
rnorm(5, mean = 100, sd = 15) # 5 normal variates with mean 100, sd 15
| Concept | Definition | Pharmaceutical Example | Reducible? |
|---|---|---|---|
| Variability (aleatory, intrinsic) | Real differences between units or events, part of the system itself. | Weight of 100 tablets from the same batch: values will never be identical, even in a stable process. | ❌ Not by measuring more, only by improving the process. |
| Uncertainty (epistemic, knowledge-based) | Lack of knowledge about the true value of a parameter or about the model. | We do not know exactly the true standard deviation of tablet weights; we estimate it from a sample. | ✅ Yes, by collecting more data or refining the model. |
Practical Note
Figure 2.1 – Transformation process: from raw uniform random numbers to model-based random variates.
Generate uniform random numbers.
Apply a transformation (inverse CDF or algorithm) to match the target distribution.
Obtain random variates that reflect the desired model.
Example in R – Transforming Uniform → Normal
u <- runif(1000)
x <- qnorm(u, mean = 50, sd = 5)
hist(x,
main = "Normal Variates from Uniform Random Numbers",
xlab = "Value",
col = "lightblue",
border = "white")
➡️ What happens here?
qnorm) to transform them into values that follow a Normal distribution (mean = 50, sd = 5).🔎 Note – What is the inverse Normal CDF?
The inverse Normal CDF (also called the quantile function) tells us:
“Given a probability p, which value x of the Normal distribution has that cumulative probability?”
For example, the 0.975 quantile of a standard Normal distribution is 1.96 — meaning 97.5% of values lie below 1.96.
This demonstrates the core idea:
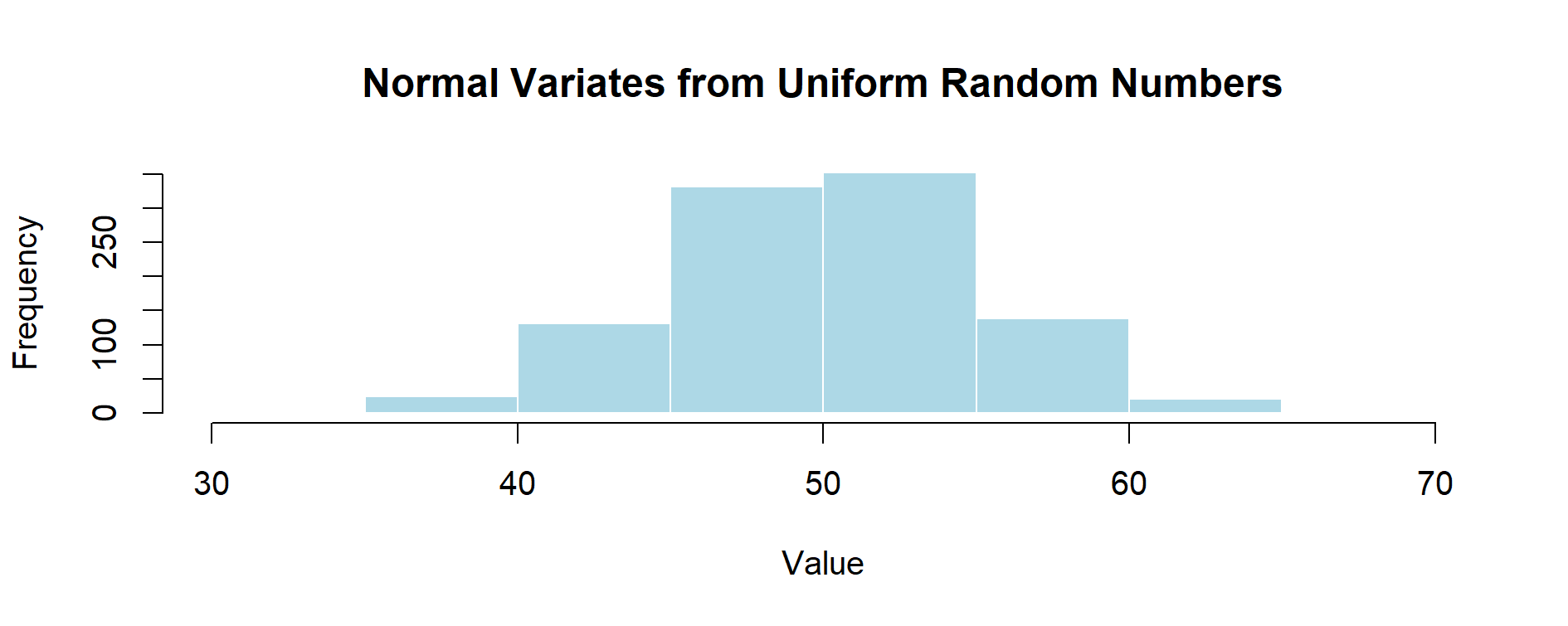
Figure 2.2 – Transforming Uniform Random Numbers into Normal Variates (mean = 50, sd = 5).
📌 Historical Note — Random Numbers vs Random Variates
In early simulation texts (e.g., Rubinstein, 1981), the term random numbers was often used broadly, referring both to
- uniform sequences U(0,1), and
- sampled values from target distributions.
Modern usage (2025) makes a clearer distinction:
- Random numbers = pseudorandom draws ∼ U(0,1),
- Random variates = transformed values from those numbers (e.g., inversion, Box–Muller, rejection).
This two-step view is pedagogically useful: it emphasizes that every random variate is ultimately built on top of uniform random numbers.
📊 Random Numbers vs Random Variates — Rubinstein (1981) vs Modern View (2025)
| Aspect | Rubinstein (1981) | Modern View (2025) |
|---|---|---|
| Terminology | Uses random numbers broadly, covering both uniforms and variates | Clear separation: numbers = U(0,1), variates = transformed values |
| Definition of numbers | “Independent random variables uniformly distributed over [0,1]” (p. 11) | Numbers from a PRNG, ideally i.i.d. U(0,1) |
| Definition of variates | Mentions “stochastic variates” but without stressing the intermediate role of uniforms | Explicit: variates are generated from uniform numbers via inversion, Box–Muller, rejection |
| Pedagogical clarity | Implicit two-step process assumed | Two distinct layers emphasized for teaching |
| Example | Sampling directly from exponential or normal without detailing the uniform step | Example: U∼U(0,1); X = -λ⁻¹ ln(1-U) → exponential variate |
| Why the difference? | Terminology less standardized; focus on algorithms | Modern pedagogy highlights the distinction for clarity |
In pharmaceutical applications:
👉 This distinction is fundamental: all Monte Carlo simulations in GMP contexts are ultimately based on random variates, not raw random numbers.
This foundation is essential for moving forward. In the next chapter, we will explore the most common probability distributions used in pharmaceutical applications.
| ← Previous: Introduction | ▲ back to top | Next → Simple Distributions |